
WeatherMesh-2 (WM-2) is a transformer-based AI weather prediction model, capable of predicting a wide range of weather variables over the whole globe, at a range of different resolutions and 14+ day lead times. Like many other AI-based weather models, the primary training dataset is ERA-5, but a number of other data sources are used as well. WM-2 predicts geopotential, temperature, winds, and moisture at 25 vertical levels, as well as a large number of variables at the surface: 2m temperature and dewpoint, 10m and 100m winds, minimum and maximum temperatures, precipitation, solar radiation, and total cloud cover.
WM-2 is a very computationally efficient and lightweight weather model, while beating all other weather models that we have compared against on RMSE metrics (see results section). A 14 day global forecast at 0.25 degree and 6-hourly resolution can be computed in just 12 seconds on a single RTX 4090. This is roughly 100,000 times faster than a physics-based numerical weather model. On a single H100 server, hourly global forecasts out to 14 days can be computed in under 10 seconds WM-3, releasing in Q1 2025, will be able to do roughly the same, while being capable of forecasting at arbitrarily high spatial resolutions over regions of interest.. While raw speed at this level is not the primary point of concern for weather modeling, computational efficiency while maintaining accuracy at this level allows for very large ensembles in the future.
WeatherMesh consists of three high-level blocks: An encoder, a processor, and a decoder. For each block, we can train multiple variants, and they all interact with the same latent spaceThe term "latent space" can best be understood as an AI model's compressed internal system of representing data. For WeatherMesh, think of it as the model's own "mental picture" of the weather, where complex patterns are represented in a format that's efficient for the AI to work with. In order for WM-2 to forecast familiar weather measurements like temperature and wind speed, it will first think about the problem in latent space, then the decoder will translate WM-2's forecast out to the physical space, which is how humans think about weather. and can be used in a number of different modular combinations. The primary input to the model is weather variables on a regular grid around the entire globe, and the output is a forecast for the entire globe at a time in the future. Each block leverages a Neighborhood Attention-based 3D transformer. The encoder and decoder additionally contain a number of convolution resnet blocks with up and down convolutions in a U-net style that deceases resolution while increasing latent dimension, followed by a few transformer layers. The processor consists entirely of transformer blocks.
A defining feature of WeatherMesh is that a processor (or a combination of processors) can be ran autoregressively an arbitrary number of times inside the model latent space, allowing for forecasting at any time horizon without doing an encode and decode step in the middle. Thanks to a number of GPU optimizations described below, we can do this arbitrarily large number of prediction steps while training the model and storing activations for the backward pass. In practice, we typically forecast out to a maximum of around 1 week in training for a medium-range optimized model. This is much longer when compared to Google DeepMind's GraphCast, which was autoregressively finetuned to 3 days (despite having more accelerator memory), and compares favorably to Microsoft's Aurora, which uses 4-10 days but using low-rank adaptation and a replay buffer, instead of using end-to-end gradients of the whole model like WeatherMesh is able to.
Keeping the state of the atmosphere in the latent space has three main advantages. 1) It avoids accumulating error introduced by encoding and decoding when converting to and from the latent space, 2) it is much more computationally efficient, allowing for parallelizations during rollouts, and 3) it allows for a more flexible and modular architecture of different types of each block, all of which communicate via the same latent space. This allows the model to learn a rich representation of the atmosphere in its latent space, and to learn the underlying physics of the atmosphere.
WeatherMesh outperforms operational models including ECMWF's HRES and NOAA's GFS, as well as state-of-the-art AI models including GraphCast, for nearly all surface and upper-air variables and at nearly all forecast lead times up to 14 days.
We calculate the latitude-weighted RMSE score of forecasts by WeatherMesh against ERA-5, ECMWF's reanalysis dataset that is broadly considered as the best "ground truth" data for global weather. We reserved the year of 2020 as the test set following the convention in the AI-based numerical weather prediction community. We compare this with the RMSE score of forecasts produced by ECMWF's Integrated Forecasting System (IFS HRES)—the gold-standard numerical weather prediction system—against HRES analysis, for the same time period As WeatherMesh is trained on ERA-5, it is natural to compute RMSE with ERA-5. However, ERA-5 is not available in real time, so it would be somewhat unfair to compare HRES forecasts with ERA-5, which would imply non-zero RMSE even at hour zero. There is no perfect solution for this, but the industry standard is to compare HRES forecasts with HRES's own analysis, guaranteeing zero error at hour zero. The difference is only noticeable at short lead times. . The results are shown in Figure 2.
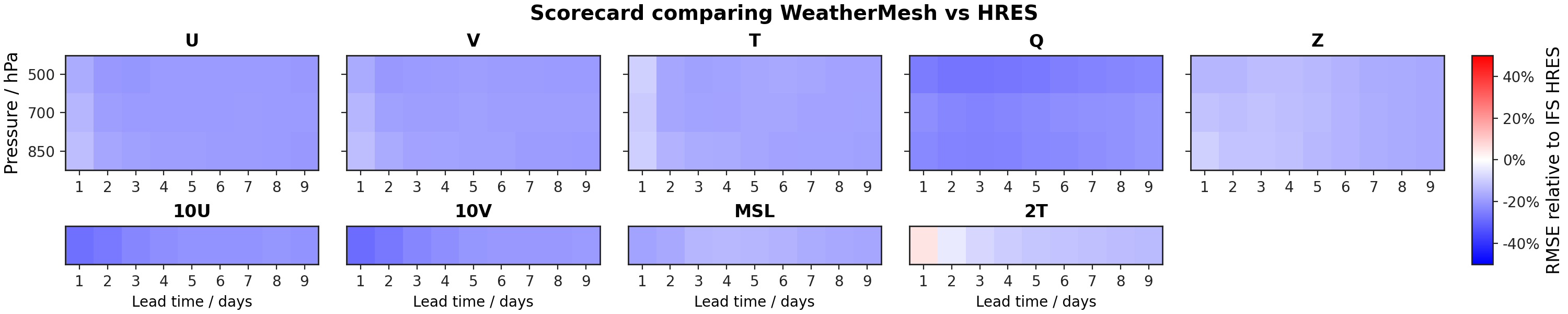
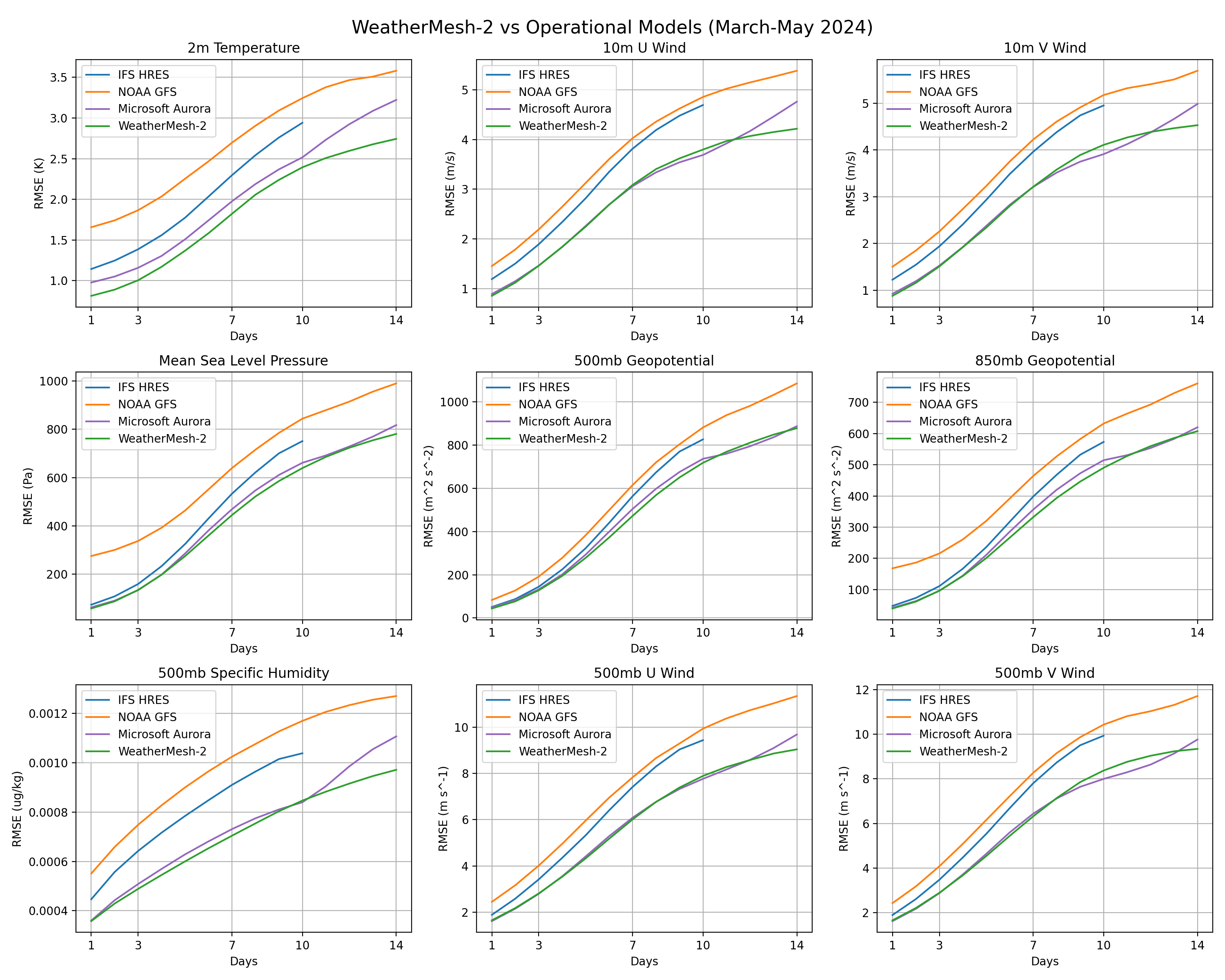
We additionally fine-tune WeatherMesh on analyses from both IFS HRES as well as NOAA GFS. This enables WeatherMesh to be run as an operational model that produces live forecasts every six hours. We also compare the performance of the fine-tuned version ("Operational WeatherMesh") with other operational models, over the period of March to May 2024. Again we find that WeatherMesh outperforms both operational HRES and GFS for all variables and lead times. HRES only produces forecasts for lead time up to 10 days; we see that WeatherMesh's 14-day RMSE score is comparable to if not better than HRES's 10-day RMSE score across variables. These results are shown in Figure Y
We also show comparison with Aurora at 0.25 degree resolution, a foundation model for the atmosphere developed by Microsoft in 2024. Aurora is considered the state of the art at a number of atmosphere prediction tasks, including global weather forecasting at 0.25 degrees. Here we compare with the operational version of Aurora for the same time period. Across different headline variables and lead times, WM-2 outperforms or is as good as Aurora on 79% of the targets evaluated Here "as good as" is defined as the RMSE score of WM-2 is within one standard error from that of Aurora. , while being 1/4 the size by parameter count and near 30x faster in inference time WM-2 has 328M parameters whereas Aurora has 1.3B. Aurora reports 1.1 seconds per hour lead time on a single A100 GPU; WM-2 achieves 0.037 seconds per hour lead time on a single RTX 4090. .
To further validate the performance of WeatherMesh, we conducted a number of case studies on interesting and relevant weather phenomena around the globe. Check out our new blog post on WeatherMesh case studies!
We compare WeatherMesh's temperature forecasts with actual temperature observations from METAR weather reports, which are collected every hour from airports around the world. We conduct this study for both winter and summer 2024, and compare WeatherMesh's performance again with IFS HRES.
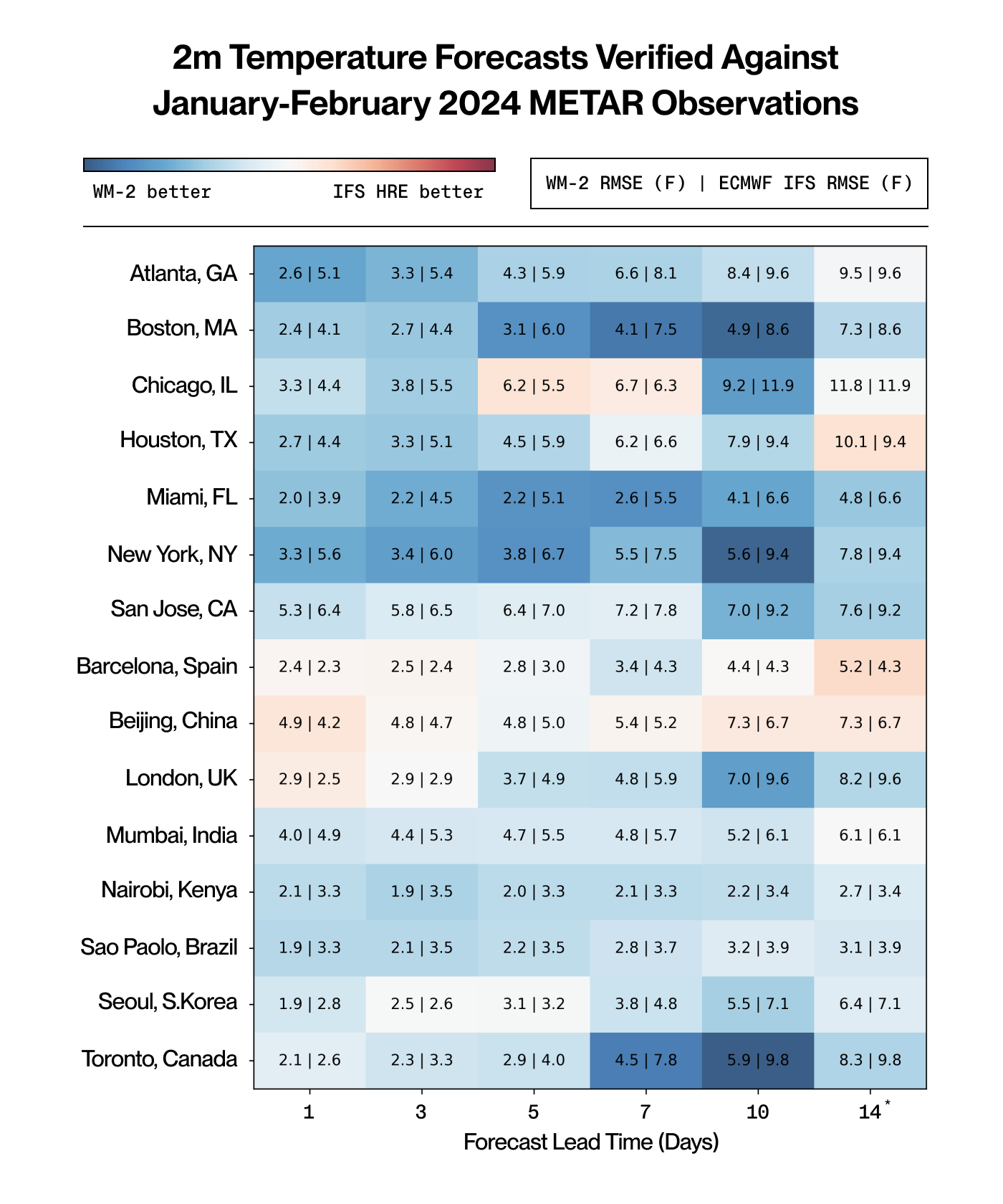
We find that WeatherMesh outperforms IFS HRES in nearly all cities, and nearly all forecast lead times, from 1 to 14 days. Again, WeatherMesh forecasting even 14 days ahead nearly always outperforms IFS forecasting only 10 days ahead. We are pleased to see that the performance is high across the globe, without gains concentrated only in particular regionsMembers of the WindBorne deep learning team, with four different countries of origin, enjoyed getting the chance to check WeatherMesh's performance in or near their home cities.. Note also the strong performance for Toronto, Canada and Boston, MA in January-February 2024, illustrating particular strength in temperature extremes.
The Encoder and Decoder convert between physical space and latent space. The primary input to WeatherMesh is an analysis from ERA-5, HRES, or GFS. The high resolution pixels of the input analysis are convolved down to lower resolution, high latent dimension patches into the WeatherMesh latent space by a series of convolutional layers.

The 2d surface inputs and the 3d inputs at pressure levels are handled by separate convolutional blocks. A bunch of additional constant or on-the-fly computable values are added to the 2d inputs, things like elevation, terrain masks, incoming solar radiation, and time of year.

The result of encoding is the Latent space. The latent space of WeatherMesh is a (B,D,H,W,C) shape tensor where B is batch time, D is depth (vertical pressure levels), H is height (latitude), W is width (longitude) and C is the latent dimension. Depth is organized from low pressure levels to high, and the last element of the depth dimension is encoded and decoded from/to surface variables. Physically, this makes sense as the surface is at the highest atmospheric pressure.
The latent space tensor represents the state of the weather over the entire globe. All of the information about the atmosphere must be conveyed and processed through this latent space, as this is the fundamental information bottleneck of the model. WeatherMesh is intentionally designed this way, as the latent space is the residual stream of the transformers, and it is the fundamental information highway in the model. Multiple different encoders, decoders, and processors can be trained to interact with and share information via this common latent space.

The decoder of WeatherMesh is essentially just the inverse process of the encoder. The processor is simply a number of transfomer layers in a row.
The backbone of WeatherMesh 2 is a series of neighborhood attention-based transformer blocks. This is the biggest architecture change between WM-1 and WM-2, WM-1 was SWIN-transformer based, and NATTEN is a large upgrade. The neighborhood attention mechanism provides a better inductive bias to the model for learning physics due to its consistent locality of attention for information transfer between patches. In addition, thanks to the performance of the NATTEN library with Fused Neighborhood Attention kernels, NATTEN is faster and lower memory footprint than our prior SWIN implementation.
To make NATTEN work on a sphere, we implement our own circular padding. At the poles, we use the bump attention behavior from NATTEN. For position encoding of tokens, we use Rotary Embeddings.
In the default configuration of WeatherMesh 2, the NATTEN window is 5,7,7 in depth, width, height, corresponding to a physical size of 14 degrees longitude and latitude. WeatherMesh 2 contains two processors: a 6hr and a 1hr processor. Each is 10 NATTEN layers deep.

Identical in architecture to our ERA-5 encoder, we have separate encoders for the realtime IFS HRES analysis and NOAA GFS analysis, as these would have different variable distributions compared to ERA5. These encoders are trained while keeping the processor and decoder fixed - the 2 analyses are converted to the latent space, added together, and then the processor and decoder are run as before to generate a forecast. This enables WeatherMesh to best utilize information from both physical models operationally and produce more accurate live forecasts every six hours.
WM-2 is trained with the distributed shampoo optimizer. We get significantly better performance with a preconditioned optimizer than with a simpler optimizer such as AdamW. Weather forecasting is particularly well-suited to second-order based optimization methods, because the models are relatively small compared to the input data.
WM-2 is trained in a number of cycles, with a main pretrain followed by various fine-tuning cycles for operational use or different timesteps. The main pretraining cycle is typically 50k to 80k steps long with a cosine annealing schedule for the learning rate. During pretraining, we start with just a simple 6 hour timestep, and then progressively lengthen the forecast horizon out to 6 days over the course of training. We also predict a number of intermediate timesteps. So, at one point in training we may be predicting out 72 hours, and doing 5 random timesteps between 0 and 72 hours. This ensures that the model is consistently exposed to making forecasts of all different intervals throughout the training process.
Weather Forecasting poses a unique set of compute challenges for training and inference when compared to other applications of AI. The actual parameter size of a competitive AI-based weather model can be quite tiny if it's architected well. WeatherMesh-2 is only ~180M parameters for the main encoder, processor, and decoders that are trained in the initial pre-training run. However, a single training sample requires a lot of computation: one cannot predict weather for only half of the globe at a time, the entire globe must be forecasted at once as it is an interconnected system. Weather over the entire earth is a much larger input than say, a passage of text in the context window of an LLM or an image. For this reason, we currently train with only a batch size of 1.
It is not possible to train a global weather model without careful considerations of VRAM utilization. Storing the intermediate model activations for a backwards pass for even the shortest forecast step would immediately would take hundreds of GiB of VRAM if done naively. As is common practice, we opt to do model checkpoints for the main transformer blocks to dramatically save VRAM at the cost of longer backwards pass compute time. This works, but it breaks down for training longer forecast time horizons.
The challenge with conventional checkpointing is that it requires storing the input to the checkpointed layer. For a transformer, this means storing the latent space for each transformer block. A 6 day forecast requires running over 200 transformer layers, so for a latent space of 200MiB, this quickly takes up 40GiB of VRAM just for these tensors alone. WeatherMesh 2 was trained entirely on RTX 4090s due to their very attractive cost per compute, and so this would be entirely unworkable.
The solution is an additional step over just checkpointing. Rather than keep the input tensor to a checkpoint on the GPU, we send it back to the CPU to be stored in RAM, a much more abundant resource. Because forecasting longer in time simply means calling more checkpointed transformer layers, this method means that there is zero VRAM cost to longer forecasting during training time, and there is effectively no limit.
We created a forked version of the pytorch checkpoint libraryWe plan to opensource this library in March of 2025 which we've named matepoint checkmate, checkpoint to implement this concept. There are a few computational considerations required in order to do this without slowing down training. First, tensors must be sent back to the GPU on an independent CUDA stream to allow for full parallelization. Second, tensors that are needed during the backwards pass must be pipelined so that they arrive on the GPU before they are needed. If tensors were only moved as needed naively, then this would incur a delay between each transformer layer in the backwards pass while waiting on tensors to arrive. The below diagram shows screenshots from NVIDIA Nsight showing how matepoint moves these tensors around.

